こんにちは。今回は、C#とSeleniumを使ってブラウザ操作を行っていた際に遭遇したエラーと、その解決方法についてまとめます。
発生したエラー
SeleniumでChromeブラウザを操作しようとした際、以下のコードでエラーが発生しました。
var chrome = new ChromeDriver(driverService, options);
エラーメッセージは以下の通りです。
System.ComponentModel.Win32Exception: ‘An error occurred trying to start process
‘C:\Users\****\bin\Debug\net9.0-windows\chromedriver.exe’
with working directory ‘C:\Users\***\bin\Debug\net9.0-windows’.
指定されたファイルが見つかりません。’
原因
エラーメッセージから判断すると、chromedriver.exe が指定されたディレクトリに存在しないことが原因です。
Seleniumは、ブラウザ(この場合はChrome)を操作するために、対応するWebDriver(chromedriver.exe)が必要です。
通常、このWebDriverを手動でダウンロードしてパスを通す必要がありますが、これが適切に設定されていない場合、上記のようなエラーが発生します。
解決方法
エラー解消には、以下の手順を試してみてください。
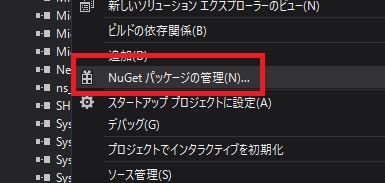
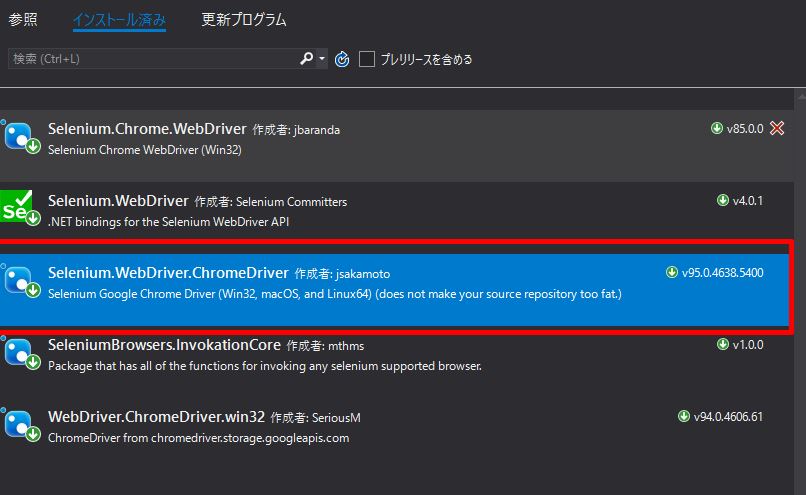
NuGetパッケージをインストール
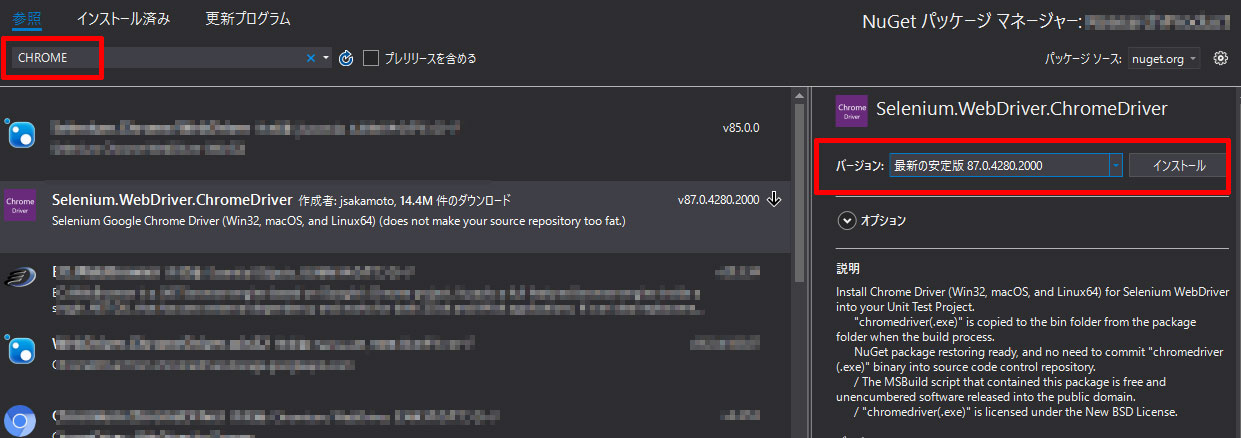
Visual Studioの「NuGetパッケージ管理」から、Selenium.WebDriver.ChromeDriver (作成者:jsakamoto)をインストールします。
Install-Package Selenium.WebDriver.ChromeDriver
このパッケージをインストールすると、chromedriver.exe が自動的にプロジェクトの bin/Debug フォルダ内に配置され、手動設定が不要になります。

コマンドラインからのインストールだけではなく、NuGetパッケージの検索画面で、 Selenium.WebDriver.ChromeDriverと入力し検索してからのインストールでも良いです。
ChromeDriverの初期化コードを確認
パッケージインストール後、コードも確認しておきましょう。例えば、ChromeDriver の初期化部分は次のようにシンプルに記述できます。
var chrome = new ChromeDriver();
driverService や options を指定する場合でも、ChromeDriver が正しいパスから chromedriver.exe を見つけてくれるようになります。
まとめ
ブラウザ自動操作で「指定されたファイルが見つかりません」というエラーが出た場合、手動でWebDriverを配置する手間を省ける Selenium.WebDriver.ChromeDriver パッケージを導入するのが簡単で確実です。
エラーで悩んでいる方は、ぜひ試してみてください。