
私たちは普段インターネット上でキーワード検索を行っています。
さらに最近ではブラウザの機能向上により検索したホームページ上でさらにキーワード検索を行うことが出来ます。
このような検索技術は大変便利であるがために、先人たちの知恵によって検索技術が格段に進歩しました。
今では技術者くらいしか扱わない「正規表現」という知識を用いた検索技術も身近になってきました。

ここで、正規表現について簡単に説明すると、曖昧さを持つキーワードを検索するための工夫です。
例えば文章から「SmartPhone」を検索するために「SmartHone」と検索しても通常の検索では見つかりません。
なぜなら、キーワードが完全に一致していないからです。
しかし、正規表現を用いると、PhoneだったかHoneだったかは別において、「Smart(P|)hone」として検索をするとこの’P’があるかどうかといった曖昧さを回避することが出来ます。
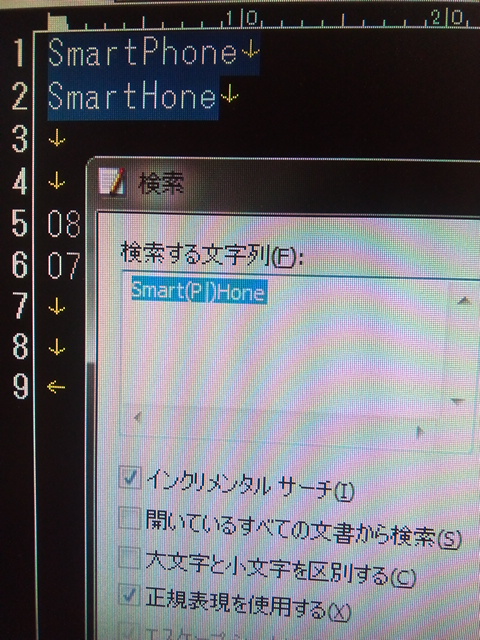
そして結果として「SmartPhone」と「SmartHone」の両方を見つけることが出来ます。
これが、正規表現の魅力です。
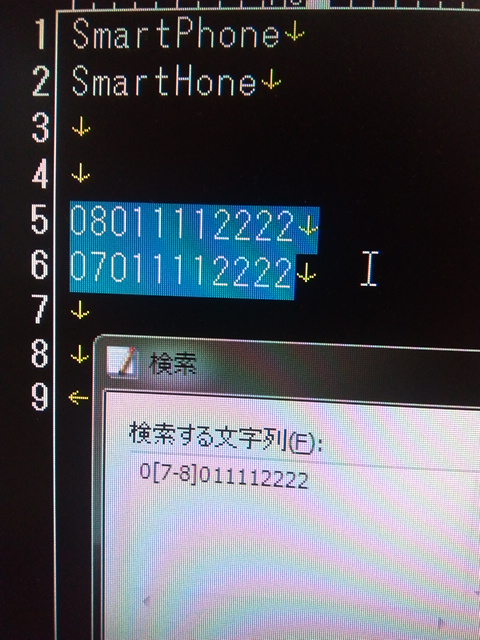
その他にも、電話番号のある1桁の数値を覚え忘れてしまってもその程度の曖昧さであれば見つけ出すことも可能です。
例えば「08011112222」だったか「07011112222」だったかで忘れてしまっても、検索欄に「0[7-8]011112222」とすれば、両方のキーワードを含む文字列を検索してくれます。
さらに応用すると、アルファベット文字と数字、ハイフンを含む文字列パターンだけを見つけることが出来ます。
その正規表現は「(A-Za-z0-9-]+)」です。一見して複雑そうですが、これはまだまだ簡単な方です。
もともと、古くからはワイルドカードといって不明な文字を*として検索をかける仕組みは以前からありました。
ところが、Web開発の途中でPerlやPHPといった文字列を扱うプログラミング言語が登場してからは、人の目で確認するのにも限界があるということで正規表現という手法が編み出されたといわれています。
正規表現をマスターしておけば文字列の編集をする上で効率が非常に良くなります。
また、現在の有名なプログラミング用エディタには正規表現の機能が備わっています。
しかし残念なことに、まだ正規表現は正式には規格化されておらず、検索するエディタによって正規表現の形式が異なります。
とはいっても、今後文字列に検索をかける上で完全一致型の検索はミステイクにもつながりますから、少なくともワイルドカードという存在だけでも覚えて使ってみて欲しいと思います。
また、更に興味があれば是非、正規表現もマスターしてみて下さると幸いです。
